Public Channels
- # general
- # github
- # random
- # resources
- # shitty-linkedin
- # trello
- # xtra-ai
- # xtra-devops
- # xtra-drip
- # xtra-finance
- # xtra-gaming
- # xtra-going-out
- # xtra-highdeas
- # xtra-music
- # xtra-professional
- # xtra-random
- # xtra-side-projects
- # xtra-smart-home
- # xtra-tech-news
- # xtra-til
- # xtra-travel
- # xtra-wakatime

set the channel description: Sharing information (resources, tips etc) on devops
hey -- any advise on the best way for testing chef recipes? I can't really use the test dev because its literally a recipe for dir creation on a blank server. I was thinking of using a virtual machine to test on my workspace

Yeah, we use a tool called Vagrant to spin up a VM and apply our recipes to it before trying it on test/dev

bingo that sounds good, but setting up a whole vagrant instance for this might be a bit much
and Vagrant installs an app called Oracle VM VirtualBox


it's so you can fetch files remotely and specify where to place it on the node
okie, chef teased me and created the tar file I needed from a repo... but it was empty
okay, no worries. I am trying to create a process for devs to instantiate a env on their machine with containers but, there is custom features and I need to figure out how this would even work because most of our OS are linux and lots of people have windows so that is a problem.

does anyone have any good introductory material to MapReduce?

@andelink Here is the book that our team's architect gave me for learning Hadoop (https://play.google.com/books/reader?printsec=frontcover&output=reader&id=661sCgAAAEAJ&pg=GBS.PA0). It's licensed to him and has his contact info on it, so don't spread it around, but feel free to use it yourself 🙂 Let me know if this link doesn't work.
It's because it's a in my google play books library, so I guess other people can't access it. I'll try to export as pdf or something.
Again, please don't distribute the pdf since his contact info is on it 🙂
@spkaplan hey sam thanks for sharing! i am excited to go through it
wait @spkaplan do you know it is over 500 pages long?
Haha yeah, it's not a starter guide. More like the definitive reference. I jumped around through the book to get the parts I needed, but I ended up reading a lot of it.
re-entering the world of bash scripting.... can you guys recommend your favorite command line text-editors?
For quick edits on the command line Vim is great if you take the time to learn how to use it. With the steep learning curve though, it's a time sink. Otherwise, other text editors are going to offer code completion and other features that just aren't available on the command line. When I write bash scripts I just do it in Atom and then keep a bash window open next to it.
I guess we need to clear something up. @andelink are you limited to the command line, or can you use any text editor?
it's a bitch copying+pasting to and from command line so i just want to stay in
When you copy pasta in Vim, remember to have it on insert mode. Or else it won't pasta everything.
You shouldn't have to copy/paste anything? Not sure what you mean. But yeah, if you are constrained to the command line, Vim is great if you have learned how to use it. You can also use nano or something like that but it's not that great. Vim is really the only way to go on the command line.
oh sorry i should have mentioned that I am connecting to remote hosts and will be working there
i could write/save files locally and then push them to the host but i am just playing around at the moment
Yeah, for working remotely, it's worth doing it on the command line. Iteration is too slow if you have to scp to test every change.
thanks guys. i think i remember using nano for small edits back at western. will try that and vim


what % of your time do you guys spend on code reviews? i am new to it but it takes up so much time its kind of insane
It depends a lot on the code review and how relevant it is to me. I should probably spend more time and participate more than I do currently but I agree, it can be a big time sink.
It definitely does take up a lot of time. I probably ROUGHLY spend about 1 day's worth of time every sprint (2 weeks) on code reviews.
it's a great way to learn, see how others do things, and stay knowledgeable about different systems, but definitely spending more time on this than i thought i would be
I agree, I learn a lot through code reviews. I find it necessary, because otherwise I won't be familiar with the changes my teammates are making to our components.
Yeah if you want to be an effective team member you have to do them
It looks fun, right!? But I don't think I'd want to have all of that flashing on a regular basis
haha no. It's fun for a couple minutes and that's about it. My keyboard is programmable like that as well but I didn't splurge for the RGB version so my patterns are just always in red.
@keenin The component I am designing is basically a driver/coordinator that will be responsible for running multiple very long running processes on a schedule. In addition to a Jenkins solution and a Java web service solution, I am looking into an AWS-specific solution. From what I've read so far (still have more reading and experimenting to do) it seems it is a common approach to use AWS Step Functions to build a series of steps to execute. Step Functions manages the workflow, retires, error handling, etc... of the downstream calls it is making. To accomplishing the "scheduling" requirement, I am looking at AWS CloudWatch as a way to trigger the Step Functions state machine on a schedule. It seems like this is a fairly standard method to solve this kind of problem. But I'd like to hear anything you know about CloudWatch that isn't particularly apparent from the high-level documentation. Any hidden trouble areas, advantages, quirks, etc...
From what I've seen around my office, people tend to use it for a bit and then realize it's not that great/there's a better solution. We mainly deal with trying to get logs out of CloudWatch (kind of a pain). Typically people use lambda functions and CloudWatch together.
Which do they use and then realize there's a better solution? Step Functions or CloudWatch?
That's good to know. Can you give me more details about what the pain points are?
My understanding was CloudWatch was primarily meant for logging/monitoring of all your AWS processes, rather than triggering of events, but I could be wrong
lol yeah i've only used it for monitoring but i haven't had the opportunity to set any of it up - only consume it.
i just learned of them and it is better than
echo 'asdfgasdf' >> some_file
echo '124351245' >> some_file
hmmm not sure quite understand what they are. Or maybe I already knew what it was and just didn't know the term for it? haha I don't know. Is your second code snippet an example of heredocs?
it treats everything after the << EOF and before the second EOF as a file and redirect its content as input to the command preceding the <<
So the following appends the two lines of content to somefile:
cat >> somefile << EOF
asdfgasdf
124351245
EOF
while the following just echos it back to stdout:
cat << EOF
asdfgasdf
124351245
EOF
Ok, that makes sense I guess. It's kind of like a short hand trick for lining up a bunch of text/tasks/scripts for manipulation
i'm using it to refresh my aws credentials upon start up in my ~/.zshrc script:
cat > ~/.aws/config << EOF
[profile alexa]
region = us-east-1
[profile bt]
region = us-east-1
EOF
cat > ~/.aws/credentials << EOF
[alexa]
aws_access_key_id = $(odin-get -t Principal $ALEXA_MATERIAL_SET)
aws_secret_access_key = $(odin-get -t Credential $ALEXA_MATERIAL_SET)
[bt]
aws_access_key_id = $(odin-get -t Principal $ODIN_MATERIAL_SET)
aws_secret_access_key = $(odin-get -t Credential $ODIN_MATERIAL_SET)
EOF
andelink: why don't you need two opening carrots following cat like in your previous examples?
here i am wanting to overwrite the whole file rather than append
So in your .zshrc file, the here-doc is allowing you to mimic a file format with the ability to use bash commands/variables. Where using a regular file wouldn't let you use those commands/variables?
keenin: It's more of just a short hand for passing a bunch of lines of text to a given command where each line is treated as a separate file and handled independently. In his zshrc example, each of the three lines under EOF is treated as a text file passed to cat. cat then echoes that file to the redirected output which is his credentials. It doesn't actually give him any additional functionality/commands.
It's not treating each line like a file, it's treating everything in between the EOF tags as a file.
Sort-of I guess (just learned of it an hour ago so still learning). I am primarily using it to avoid doing this:
echo "[profile alexa]" > ~/.aws/config
echo "region = us-east-1" >> ~/.aws/config
echo "[profile bt]" >> ~/.aws/config
echo "region = us-east-1" >> ~/.aws/config
echo "[alexa]" > ~/.aws/credentials
echo "aws_access_key_id = $(odin-get -t Principal $ALEXA_MATERIAL_SET)" >> ~/.aws/credentials
echo "aws_secret_access_key = $(odin-get -t Credential $ALEXA_MATERIAL_SET)" >> ~/.aws/credentials
echo "[bt]" >> ~/.aws/credentials
echo "aws_access_key_id = $(odin-get -t Principal $ODIN_MATERIAL_SET)" >> ~/.aws/credentials
echo "aws_secret_access_key = $(odin-get -t Credential $ODIN_MATERIAL_SET)" >> ~/.aws/credentials
Or you could echo with a newline \n.
echo "[profile alexa]\nregion = us-east-1\n[profile bt]\nregion = us-east-1" >> ~/.aws/config
oh yeah that would have been better than an echo on each line as well
it's weird though supposedly there is ideally one right way to do something but there are so many different ways to do the same thing
A Facebook recruiter reached out to me about a Data Engineering role there and sent me their standard pre-interview questions for Data Engineering (meant to be practice material). It's a fucking breeze.
I'm talking with a FB recruiter again and they sent me this exact same set of homework questions today. The exact same questions from two years ago.
@andelink uploaded a file: facebook_de_sql_questions.docx
haha yeah, that's some entry level shit. Do they know you are experienced and do that stuff everyday?! I wonder what an offer from facebook would look like. I think they have a pretty good comp package
i mean the guy saw my linkedin and reached out to me, so i assume that they know/think i am experienced in this. it was so basic
Haha yeah, I mean I would have to look up how to do some of those queries but those must be like second nature to you by now. Have you responded to their email? Did they say what level the position was that they were interested in interviewing you for?
They didn't say anything regarding level. I spoke with them on the phone before they sent the practice material and told them I wasn't considering leaving Amazon yet - but still wanted to see their practice material.
Based on what they sent, I can't imagine it being for anything above entry-level
@andelink uploaded a file: facebook_de_coding.py
Nice. Did you send in your solutions or just do them for fun? And are those two complete sets of solutions?
Nah I just did them last night to try them. I tested the python ones and they worked (test with the assert statements), but I didn't verify the sql ones because I didn't want to create tables just to test

Should be interesting going to work tomorrow @spkaplan
@andelink Yeah, I'm waiting for more people to get into the office. I'm curious to see what we hear throughout the day
when your redshift cluster has an unrecoverable hardware failure and you need to spend your friday night on-call with aws support and restoring latest snapshot into a new cluster while re-loading old data that didn't quite make it into the snapshot and monitoring the backlog of 150+ load jobs in the queue to ensure they run in the proper order once the snapshot is restored
/gifs

Anyone have experience with the ELK stack?
haha all sorts of stuff! The biggest use case is as a searchable log store but I've also used it to store large lists of autocomplete options since the elasticsearch api has built in autocomplete functionality that is really quick and easy to set up. It's a distributed document store though. It's very quick at searching documents of the same shape since it can store the data in lots of small "shards", query them all asynchronously, and then return the aggregate data. What's your use case? I can probably help you decide if it's a good candidate solution.
A PRFAQ for a new analytics platform ended up in my inbox and was pushing to build it with ELK but I disagree with it being the right tool for the job. The whole document conveyed very little technical competencies.
Was wondering if anyone here has worked with it. What you've mentioned confirms my thoughts
It depends on what your goal is and requirements are. At its core ES is a full text search engine. It’s distributed and indexes everything heavily, making it strong for real time query retrieval. But since it is full-text it is a bit more than a document store (A fuzzy-wuzzy dynamodb, a restful mongodb).
It is schemaless so it lends itself to log analysis easily.
It has some simple aggregations which makes Kibana possible, but lacks any complex analytical functions and doesn’t handle joining different data sources well. Doesn’t make it a good solution for traditional business intelligence, ETL, dimensional modeling, or slicing/dicing/drill-downs. See typical relational databases (oracle, Postgres, Redshift, etc) and reporting applications.
It isn’t in-memory so it’s not good for your usual data science or ML tasks (model training is an iterative process). See Spark, Hadoop, etc (also decent general purpose ETL frameworks).
Depends on what you need to accomplish. Seems like a great fit for real-time operational intelligence, but not your usual massive ETL/aggregation/reporting that is associated with business intelligence or data cleaning/formatting and model training associated with data science
It’s awesome you get to use elasticsearch! I want to see it in action
Are you using AWS Elasticsearch or rolling your own with the open-source?
My team has 2 instances in AWS currently (one for a bulk of our logging which is used across other teams as well and another that handles the autocomplete for the search bar in the research center). I also have an ELK stack running on a spare dev box sitting under my desk at work which I set up as one of my first larger projects. It consumes snowplow logs () enriched with some employer data we keep in a mongo db. We use this for some of our SEO testing and analysis right now since Google Analytics samples our page views so it can be frustrating when trying to dig in and get specific.
Nice I have heard of snowplow but don't really know anything about it. The link says: Cloud-native web, mobile and event analytics, running on AWS and on-premise with Kafka.
What does mobile and event analytics mean here?
You can use it alongside Google Tag Manager which is a service that fires off events or posts variables on a web page when certain conditions are met. Snowplow captures all of those variables on the page and turns them into logs. So, each page load becomes a specific log and each user session has a unique id so you can track it. I think they just used mobile because it works across all platforms but their may be features specifically for mobile analytics I'm not aware of. That's my take on it but I'm not the one that originally set it up. I just got it all piped in to elasticsearch so we could more easily analyze it.

@spkaplan commented on @spkaplan’s file https://soundstack.slack.com/files/U2494HTLP/F54JD5CAZ/hadoopinpractice.pdf: @andelink I’m glad to hear it! 😄
Does anyone know how to see the ssh-agent processes for just the current shell? ps aux | grep $USER | grep "ssh-agent" returns all ssh-agent processes for the user, not just what has been initiated in the currently active shell (e.g. if I use screen or tmux and initiate an ssh-agent in that shell, after already having initiated one elsewhere, and then use ps aux in either shell it would list both agents running)
Edit: nvm, $SSHAGENTPID returns the process ID for the ssh-agent in the current shell. this will suffice.
Does anyone use a tool at work that allows you to build a dependency graph of your services across different platforms/networks? I can easily generate a dependency graph for a set of projects that belong to the same solution but the instant an API call is made, I lose visibility into what services the service I'm calling depends on. I want to be able to answer the question, "If service X goes down, will service Y go with it". Seems kind of tough. I feel like you would need to attach tracker metadata to each DTO that goes across the network so that it could be traced from its origin. Seems pretty out there, but I just thought I'd ask.
I expect you would need to do what you suggested (doing some sort of tracing). I have not heard of any other tool/method to do it.
Splunk can do this, is just a super expensive part of their product. It's difficult, because you have to have something sitting almost everywhere that's sniffing packets and recognizing what the API calls look like.
Splunk's product works nicely because you inherently have splunk forwarder installed on every host. i.e. that agent can do all the sniffing and reporting back to the mothership.
Not quite as general as your vision, but my team uses Airflow for most of our workflows. It generates DAGs and you can visually all your pipelines and dependencies
Doesn’t discover underlying services any of your work might hit, however
Alright, thanks guys. Thought it might be a cool hackday project but it seems a little out of scope. This is the first hackday where I've showed up and not immediately known what I was going to work on 😕
Something I’ve been meaning to spend time on haven’t gotten to yet; a nice UI for data discovery and table DDL, metadata, query/load history, etc. Lots of tools do a piece or so if this as an add-on but I can’t find something specifically for this with all the features I’d like. Would be pretty straightforward to build I think
Hmmm I'm not familiar with those tools and their use cases so I'm probably not the one to take it on. Sounds like you need a hackday! haha Does anyone else's work do hack days?
We do lab week three times a year. Exactly like hack day, but a week long.
Various orgs across Amazon host hackathons that people can attend. Never been but seen plenty of posters for them

@tiaalexa commented on @spkaplan’s file https://soundstack.slack.com/files/U2494HTLP/FA23D68F2/image.png: omg so many feels rn
@brandon commented on @spkaplan’s file https://soundstack.slack.com/files/U2494HTLP/FA23D68F2/image.png: haha that's a good one
Stupid question here. Didn't take any CS so don't formally understand how long a certain operation takes. When serially iterating over say 15M+ objects, how much extra time does an extra conditional check add? Is it significant if it is just a modulo operation?
Specifically, this is what I have:
python
with NamedTemporaryFile() as tfd:
for _, tsv in filtered.toLocalIterator():
tfd.write(ensure_utf8_encoding('{}\n'.format(tsv)))
count += 1
if count % 100000 == 0:
LOG.info(' %s: %s', locale, count)
tfd.seek(0)
s3_put(tfd.name, outkey)
I'm wondering if removing the if count % 100000 == 0: LOG.info(...) bit would help shave some time off at all? Would it even make a dent?
Hopefully this can give you a ballpark estimate of how much extra time is spent on the modulo.
On 15M+ iterations, it will save some time. Not sure how much though lol.
Taking out the I/O command though will definitely save time. (LOG.info(...)) TBF thought you only write 1/100000 entries.
If anyone was wondering, here are the timeit results for iterating over 5M records 100 times:
python
>>> import timeit
>>> from tempfile import NamedTemporaryFile
>>>
>>>
>>> def test1(num_records):
... mod_check = int(num_records * 0.01)
... count = 0
... with NamedTemporaryFile() as tfd:
... for i in range(num_records):
... tfd.write('{}'.format(i).encode('utf-8'))
... count += 1
...
>>>
def test2(num_records):
>>> def test2(num_records):
... mod_check = int(num_records * 0.01)
... count = 0
... with NamedTemporaryFile() as tfd:
... for i in range(num_records):
... tfd.write('{}'.format(i).encode('utf-8'))
... count += 1
... if count % mod_check == 0:
... tfd.write(''.encode('utf-8'))
...
>>>
>>> for func in ('test1', 'test2'):
... print(func, ' : ', timeit.timeit('f(5000000)', setup='from __main__ import {} as f'.format(func), number=100))
...
test1 : 644.0622930042446
test2 : 711.0211787484586
Shaved almost 30 seconds off.
Is that significant for you? How long of a task is this in total? Also, it seems like it shaved 67 seconds unless I'm reading this incorrectly?
This is being done in a Spark job, and the real bottleneck is the network transfer of the data. I was just curious about this
Do any of you do personal programming projects on the side? If so, what do your dev environments look like?
For the time being my work projects have been fun, so if I have had the urge to do coding outside of normal office hours, I still work on work projects.
What about you?
That's been the case for me so far as well. But today I've been looking into setting up my own personal development environments and wanted to ask you all about any experience you have with that.
For me I think it depends on what technology I'm using for the project.
Yeah I haven't been spending much time outside of work on side projects but have been itching to do some front end stuff to make a portfolio site.
Noob question then. Why would it vary too much on what you’re trying to do?
In terms of IDE's- webstorm for FE, and intell-j for BE is what I prefer. More because that is what we use for work and that is what I am used to.
Some just make things easier to build and don't need to import extra plugin's so this is why I have different ones suited for specific languages
Oh yeah IDEs make sense. I was thinking more like in terms of project dependencies and workspace organization. Even that might be language dependent?
Yeah, it's pretty language/framework dependent. Some languages like python put dependency management in your hands and things can get really hairy and confusing fast while other more structured languages like C# handle a lot of the management for you. At least that's been my experience especially when I slap a full IDE on top of it.
I would just start by creating a git repo so that your project is versioned and try to follow best practices for that language. In the case of python, that probably means using a virtual environment and maintaining a requirements.txt by using --save when installing packages with pip.
Or if you want to do something way different than work and just have fun you should look at getting a starter Arduino kit or something. They are cheap and fun to play with and there is a large community around them on Reddit and whatnot where you can get ideas for projects.
Arduino kit? Is that the same sort of thing you worked on for your high school project?
It involves some of the same hardware concepts but my high school project was at a lower level than the Arduino would be. I didn't do any coding in high school but with an Arduino, there is coding involved. I had a lot of fun playing around with mine last year.
In Sprint Review... looking at teammates code on the big screen...

curious what you guys use for your CI/CD pipeline. As we move to microservices from monolithic application i think we are building out a new pipeline from chef. curious what other people use?
We use chef for managing environments and then TeamCity for building packages and Octopus for deploying those packages to wherever.
chef seems nice from what I've read. Haven't used it though.
Amazon has it's own internal CI/CD tooling. In the past couple years they've been inspirations for AWS offerings though:
* AWS CodeDeploy (internally: Apollo)
* AWS CodeBuild (internally: Brazil)
* AWS CodePipeline (internally: Pipelines)
* AWS CodeCommit (internally: our GitFarm)
The native AWS products still don't have all the features of our internal tools, so not all teams here have migrated their devops to native AWS yet. Long term our Builder Tools team is pushing for the native AWS devops.
You guys have any good resources for learning OOP?
Some of you may have already seen this in the HutchResearch slack, but figured I’d share here incase not. I always wanted to understand how it works from the ground up. This might be a cool way to do it.
Ah yeah, saw this mentioned on Reddit the other day actually. Still need to take the time to check it out though. Have you tried it yet?
@brandon Elasticsearch is slow if you index on a field that you don't use in your search/query, right?
Not necessarily. You'd want the index in your search to increase speed, but the other stuff in your search is used to narrow down the specific results (obviously slowing down the search, but a necessary).
Ideally though, yes, you would only search on indexed fields, but that's a design/philosophical problem.
Yeah this is somewhat basic DB indexing principles in play here
Had a design meeting where they changed the doc schema to index on a field we don't search on at all. We've got billions of documents here and no one is talking about the inevitable performance hit
I spent an afternoon reading about it and deploying a cluster, so I know just a little bit.
Okay. I'm just wondering if anyone can share their experience with how long simple config changes typically take. I'm enabling Cognito for Kibana authentication on a couple clusters and the time that the Domain Status = Processing seems way too long after I submit the change.
Googling doesn't help too much, mostly results of clusters hanging in the Processing state
I might just be impatient. It's taking about 20 minutes process the change.
Unfortunately, I didn't work with it enough to get a sense of how long an update is expected to take. I do seem to remember it taking a while to do some cluster changes though.
Anybody here ever used the Go language? I'm encountering it for the first time in the wild and don't know anything about it. What it's used for, why use it, when to use it, etc
Never gotten to use it but I've been interested in trying it. It's supposed to be pretty cool. That's all I've got lol
@brandon what makes you interested in it? I saw it in the middle of an internal python package here at amazon and was confused by it’s presence
Just that I had a coworker that would talk about it from time to time and that it's developed and maintained by Google. I have no idea what I'd build with it or what it excels at and I would also be confused by it's presence in the midst of a python script. Maybe someone just wanted to try it out and thought it would be a good language for the job?
Gocha gotcha. idk. Just wondering if anyone here could speak to it. Too lazy to do my own research



It's amateur hour! I've been having an issue with an assignment that I can't figure out, was wondering if any of you had any more experience with sockets than me. I've been sending information from a server to a client just fine, but now I'm trying to send some information back to the server and it's not liking it. The program is a game, but the relevant info is that it's connecting two clients to a server and each takes turns sending words back to the server.
Received 4 bytes for a word of length 4...
The word "" from Player 1 which starts with a "" and has a length of 4.
Next turn.
Received 4 bytes for a word of length 4...
The word "" from Player 2 which starts with a "" and has a length of 4.
Next turn.
Received 10 bytes for a word of length 98...
The word "dc" from Player 1 which starts with a "d" and has a length of 98.
Next turn.
Received 10 bytes for a word of length 102...
The word "gh" from Player 2 which starts with a "g" and has a length of 102.
Next turn.
As you can see, the server initially reports receiving the correct number of bytes but displays nothing. Then, it waits a full loop before reporting a different amount of bytes received and displaying part of the initial word sent.
Just another thing, it's always the last two bytes displayed no matter the length of the string sent. The order may change, but always the last two.
Unfortunately, networks is one of those topics that I would need to do some serious refreshing on before I would be of any help. We do not work at such a low-level much, if at all, so the details are not fresh on my mind.
Yea that's fair. Figured it was worth a shot. Figured it out eventually tho, it was just a wrong data type. Thanks, anyway!

SPLUNK EXPERTS (looking at @keenin) can you create an alert in splunk to trigger if a file is empty…?
I love that we have this Slack workspace to ask questions like this!
What do you mean by a file being empty? Like the log file the forwarder is reading? Or a file on the actual Splunk indexer/search head?
it’s the log file the forwarder is reading but i think i was overcomplicating it
i can just check the number of results returned that was read from the file
We use Lombok a bit. Mostly just for the @Getter and @Setter annotations, maybe a few constructors as well. It can definitely make things look a lot nicer. It has created some weird interactions, however.
It's been awhile, but the main one I remember had something to do with autowiring through the constructors that Lombok was building. Spring and Lombok seemed to disagree on what exactly was happening in the constructor, and the error that was being thrown wasn't pointing at anything too helpful. But, I feel like anytime you trust libraries to write code that you can't really see, it opens you up to running into something like that; Especially using multiple of them together like we are.

Anybody have experience with Docker and Docker Compose? I'm trying to get a couple containers with a server and db up and running and I have no clue what I'm doing. Followed the official "how to" but felt like I didn't really get why I was doing what I was doing.

Browser/cloud IDE for remote development? I’m a big fan. Excited to try this
That's looks awesome! The less I have to install on my machine the better 👍
Hey @tiaalexa, do you know a way to get or make a quicklink/url I can share with someone that takes them to "create new issue in this epic" within JIRA?
I want someone to file us a JIRA issue but I want it to be within a certain epic but I don't want them to have to worry about all that detail they don't care about.

Stack Overflow: turning 8 hour workdays into 2 hour workdays since 2008
@brandon @spkaplan @keenin @r.taylor would like your thoughts on designing tests for this recursive method I (temporarily) need.
context
my service calls a model to run inference on some input data. that’s all you need to know about that. the models response type is a deeply and arbitrarily nested object with N depth, where N is unknown and can change with each call. the top-level body has as a defined contract (as in the reponse attributes are known), but they are nested with further data types to an infinite depth with a far less strict contract.
problem
nested way within these model responses are instances of numpy.float mixed along with primitive python floats. normally not a problem. but we batch up model responses for distributed processing in spark, and apparently pyspark doesn’t know how to map numpy.float to the appropriate scala spark type for use in its execution engine. (i’ll give you a hint: it rhymes with gloat). the best paths forward would be to (i) fix this in open source spark, and/or (ii) make upstream changes to the model response. both are on the jira board, but alas, we have a project roadmap with deadlines to meet, so i relent and ship the quick fix.
the quick fix solution
a simple method i’ve so aptly named to_floats that recursively descends into nested objects and cast all float-like objects (inherits from python float) to native python float. not a problem, but it scares my teammates. we need a robust test suite in place.
testing <---- this is where i need you, thanks for reading so far
how do you design your tests? note that, in python, native equality comparisons require the objects being compared to be of the same type in order to be considered equal - except for numeric types. for numeric types, the equality operator behaves as though the exact values of the numbers were being compared, disregarding type entirely. so you get things like:
>>> 1 == 1.0 == np.float64(1.0)
True
>>> {'a': [np.float64(1.0), 2]} == {'a': [1.0, 2]}
True
now, this is what my pride-and-joy little method does:
# good
>>> to_floats({'a': [np.float64(1.0), 2]})
{'a': [1.0, 2]}
what my tests need to catch, is if it doesn’t work ie like this:
# bad
>>> to_floats({'a': [np.float64(1.0), 2]})
{'a': [np.float64(1.0), 2]}
… and so, with python number comparisons being as they are, i cannot simply rely on:
# not good enough
>>> assert to_floats({'a': [np.float64(1.0), 2]}) == {'a': [1.0, 2]}
True
# because ...
>>> to_floats({'a': [np.float64(1.0), 2]}) == {'a': [np.float64(1.0), 2]} == {'a': [1.0, 2]}
True
conclusion and rfc
to overcome this, my tests implement their own recursion to do both a value check of individual elements and a type check to ensure all nasty little np.floats have indeed been replaced with floats. i don’t like it and it feels wrong. how would you go about testing this? would you do different? the same? i’d love your thoughts. PLS HELP.
thanks in advance. application and testing code in the 🧵 -->
UPDATE: put the code in a gist
I am hoping this file gets syntax highlighting for you
Testing recursion makes everyone queasy lol. But I'd say off the top of my head that this is the correct approach.
You could always flatten the object while testing to avoid recursion, but it'll essentially be the same thing.
Side note, while yes N can be infinite in theory, in reality it won't be. So, a little bit of a saving grace 🙂


Posted using /giphy | GIF by Feliks Tomasz Konczakowski
please feel free to comment in the gist if its easier
I've never even attempted writing tests for recursive functions, so I'm not gonna give my guesses as input, but I definitely don't envy you
Wow, I'm not envious of you having to deal with a not well-defined response object. What you're doing sounds right to me. Keenin already mentioned this, but I will echo it, the only thing I can think to consider is whether you want to separate the 1) traversing and 2) to-float-ing, by flattening the object before to-floating. It's a trade-off between complexity (i.e. less complexity since you will have 2 slightly simpler pieces to test) and time/space efficiency. However, the flattening is nearly as complex and traversing and to-float, since they both require traversing the arbitrarily deep object.

almost all of my stack overflow is for shell/system dev
Ahh, okay, I guess that's fair haha you're just always so on top of these outages
Psh, I don't work for Amazon, I don't have to worry about getting PIPed
The traffic is unprecedented, we don't have the bandwidth for this kind of operational excellence. 🥵


I just found the best CLI for viewing any text-based content within the terminal: rich-cli chefkiss enjoy
Actually I made it a bookmark here because Slack is deleting old messages now
What's the difference between that and this: https://emojipedia.org/

This guy is really nice. Not only does he publish quality and regular content, he also personally asks everyone who signs up what kind of engineer they are and their experience level to help improve his curation. Pretty solid in this day and age.
Here’s his past archives of articles:
https://news.ycombinator.com/item?id=32909076
Most programmers are not like Donald Knuth. But there are a few that are. I'm one of them.
🤣😂😆😄🙂😐🙄
I’d love some some inspiration, not sure I use any macros. Are these a sequence of keyboard events that you can trigger with a keyboard shortcut? What are yours?
I just programmed my firs this morning...my email address is now 1 key press 😍
hahaha how often do you need to type your email address
Well nice. Gotta start somewhere. I don’t have any!
I have terminal triggers and aliases but not any general purpose use anywhere type of things
I usually do ⌘+K and then enter the channel/person
I’ve added a bunch of git functions and aliases, and use almost all of the different hook functions to run things whenever I change directory or execute a certain class of commands.
I’ve got too many. I’ll list some
I’ve switched to using mostly functions rather than aliases. Some of these are really old, so don’t judge. They’re ugly but they’re mine.
I’ve omitted everything necessary for triggering execution based on changing directory or what command has been entered because it’s a lot
And then I have some Lyft-specific ones for connecting to VPN, assuming different IAM roles, docker and k8s stuff
Anyone used gpt-3 api in an app/tool/project? We have a hackathon, and my team is gonna try to use gpt-3 in a slack bot to help answer customer Qs.
I'm definitely a man pages type of guy. I remember getting annoyed with Python because the man pages were so hard to find and inconsistent. Java, on the other hand, has lovely man pages.
I use man pages for CLIs. You use man pages for Python? What does that even mean really? Like man python?
I use the standard Python docs a lot docs.python.org
Been meaning to try out this though:
https://kapeli.com/dash
What does that even mean really?The docs you linked are pretty much what I'm talking about. I consider them modern man pages.
Maybe I’ve used the Python docs so long I can’t remember any pain points I might have had with them earlier on. But I don’t see what’s in the Java docs that make them better. Fwiw I don’t think I see either as being better or worse, of those two examples you link. Is it the table formatting you like in the Java docs?
Just the depth and style of the information provided. So, sure, in part the table. I don't like that the Python docs are mostly just a paragraph that minimally describes methods. The Java docs give you pretty much all the information you could ever need: inherited methods, method examples, links to all relevant objects, including parameters, extended classes, and extending classes, etc.
True, the Python docs do tend to be a bit wordy. But none of the class information is needed for your example because print is just a function. Everything in Java is a class, while not so with Python
This is a really awesome tool I’ve been using for querying apis across AWS, GitHub, Slack, JIRA, etc. Writing SQL against tables (on top of the platform APIs) then learning each platform individually and writing custom scripts for each
https://steampipe.io/
Oh I don’t know. It’s been one-off so far. But I plan to use this to query GitHub and JIRA for building a performance review report when the perf cycle rolls around. Remind me what I did and get stats on my work
Looks pretty similar but for your local machine instead of cloud resources https://osquery.io/
@andelink if/when you build query(ies) for pulling github activity for someone, i'd love to have a look at them, if you're willing 🙂
@andelink If you were to gather data from github to evaluate your performance, what metrics would you want to build? Just list of PRs, or...?
Every time I sit down to write a self-review I’m always like “I did nothing.” So it would mostly just be to help me remember what I actually did do lol
I have a list of sort of templated hyperlinks I refer to every review cycle.
Github PRs you’ve authored.
Another Github one I use is for things that involve you, but are not authored by you:
Easy to change the above for commits. You can get at PR conversations, cross team collaboration etc.
JIRA - updated, resolved, created
!= newtablehandler and key in updatedby(kandelin, "2021-06-30", "2022-01-01") order by updated desc, created desc
!= newtablehandler and assignee = kandelin and resolved > 2021-06-30 and resolved < 2022-01-01 order by resolved desc, created desc
!= newtablehandler and creator = kandelin and created > 2021-06-30 and created < 2022-01-01 order by created desc, updated desc
Confluence - created, last modified
"kandelin"+and+created+>=+"2021-06-30"+and+created+<=+"2022-01-01"+order+by+created
"kandelin"+and+lastmodified+>=+"2021-06-30"+and+lastmodified+<=+"2022-01-01"+order+by+lastmodified
Emails you sent.
source:mail after:2021/06/30 before:2022/01/01
Now sure how well this google drive/docs search is
source:drive after:2021/06/30 before:2022/01/01
Writing something in SQL and joining across all these platforms would be nice and once written make it way easier to refresh and go through your work. If you wanna be clever with numbers I could see interesting ways of getting hard data for sevs/tickets reduced after your commits, number of consumers hitting your library/service after your code rolled out, X reviews/guidance on Y external teams, dollars saved etc
I currently track what the engineers on my team do by hand (jot down when I see they are driving a big convo, author a great doc, etc...), and by User Stories. Having additional data from GitHub and other sources would certainly help jog my memory of their recent accomplishments better. I'll provide any SQL queries a write.
I hit the rate limit of 5000 requests/hour when querying github data via steampipe, have to wait 55 more minutes before making any more calls 😑
I hit the rate limit of 5000 requests/hour when querying github data via steampipe, have to wait 55 more minutes before making any more calls 😑ah bummer, hopefully you can write a more optimal query??
I was reviewing the gh env variables and it led me to a great discovery: charm.sh
They have great terminal applications, but even better they have great libraries for building terminal apps AND really great services for provisioning a backend for your terminal apps claps claps claps
- gum: gonna start using this immediately in my shell scripts
- glow: switching to this for markdown instead of rich-cli
- charm: <---- command line backend tools that i am really impressed by
I”ve been noodling with a CLI notes app for a while now and every time I’ve thought about building a backend for syncing across devices I’ve though “eh, too much work” but these charm tools look like the perfect way to do it. They built skate using charm as an example and they make it looks so easy
wish is a project of theirs for easy building of custom ssh servers/applications. They built a demo with it for folks to get an idea of what can be built with it and it’s honestly really fun to use and get you thinking about different terminal apps are possible.
I think it’s great. You can try it out for yourself:
ssh git.charm.sh
this is my personal channel stream of consciousness
no no, i totally appreciate you sharing the tools! I am confused what the tool(s) is/are from first glance 😄
However, after a few more mins of reading, i understand the highlevel goal of Charm now
gum and glow and skate are more straightforward IMO
charm is the 'platform' project. gum glow and skate are built using capabilities from charm project, right?
then the tools in charm are used to build terminal applications with a backend for user auth/storage/syncing etc. they built skate using charm
I LOVE these kind of lib projects. The more powerful libs like this the better ❤️
yuup charm is the platform project
i don’t think gum has a backend (if it does I missed it). it was with, and provides features to, their other projects bubbletea and lipgloss.
glow does have the option for a backend i believe with the stashing of documents and syncing them across your different devices.
skate built with all of them
Me too! I honestly felt floored when I was reading their charm docs. For anyone thinking about building these types of applications, charm has got to be one of the first tools you reach for when doing so
Does anyone know if a tool exists to visualize k8s clusters, ideally even including info about worker nodes, networking resources (i.e. security groups, in the case of AWS). Basically a single GUI to see all the resources in play in a k8s cluster. I feel like something like this should exist, but I'm not finding anything that seems very sophisticated or thorough.
Not much experience in this area unfortunately. It does seem like an important tool to have for such an architecture though.
We use custom dashboards with grafana. Our templates though come with a bunch of default panels for k8s specifically
What’s the longest you’ve spent debugging a test failing? I just spent ~3 hours 🙃
I don't even want to think about it, lol I'm sure way longer than 3 hours
I’ve never used a debugger in my life. And now I’m too afraid to try
https://blog.ldodds.com/2022/11/08/recreating-sci-fi-terminals-using-vhs/ I love VHS and aLalaLOVE charmbracelet ❤️

Yeah I dig it! I’ve begun replacing existing README gifs and static shell snippets with it
I want to explore the pre-commit hook to see if it’s a good way to keep the gifs updated as the code base changes
Shouldn't static shell snippets stay as text so they can be copied though?
Our READMEs use to be full of crazy specific snippets I could never remember, and I always had to copy every single time. I’ve since shipped some CLIs that handle all the nuanced specifics behind simple, easy to remember commands. And if you can’t remember the command you can print the help in the terminal.
So maybe we don’t need all the example usage as code snippets. GIFs are more fun, and, if the command response/behavior is noteworthy, more valuable.
Or maybe we do still need em. If this comes up in PR discussion I’d maybe keep the snippet alongside the GIF, or point the reader to the VHS .tape file that built the GIF and they can copy commands from there.
I wonder if forcing people to watch gifs instead of blindly copy pasting commands will improve their learning/understanding/retention
Has anyone tried k8slense?


I see a couple things I don't really like there, but curious which is the deal breaker for you in this case? Also, do you need to register in order to use the product? I haven't tried.
- registering is required in order to use the product
- billing/shipping information attached to my registration
- real name, postal address, phone number, email address
None of the above are requirements for using the overwhelming majority of other open-source projects. Seems shady to me, don't trust em
update: My coworker said he didn't have to provide any personal/billing info. i haven't tried it myself to confirm yet
I'm finally learning how oidc/saml/sso works. Found an article with a great explanation.
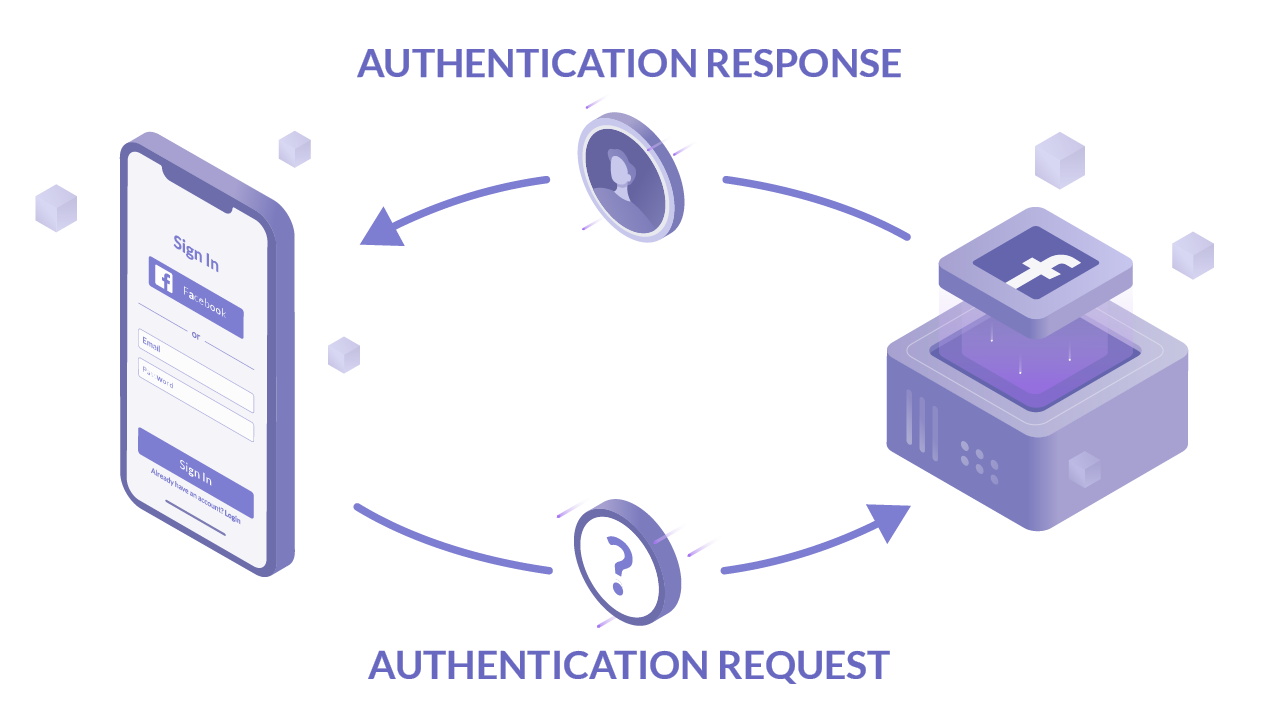
@andelink The first 1/2 of the article provides a pretty good overview and is pretty concise. Not sure a TL;DR would provide more value without sacrificing too much info.
SAML (Security Assertion Markup Language)til
World Cup soccer balls have gotten crazy advanced with this new IMU sensor in them. 500hz signals being processed in real time!! To contrast this, we use “only” 25hz signals for driver telematics

is 25hz too lossy for driver telemetrics? I know nothing about the area
It works for us! I just wish Android IMUs would be more reliable in their emitting of the sensor readings
Yeah 25hz is still a good amount of data coming off one signal. 25 data points per second that is
haha yeah that is what I thought too. I was surprised when i thought you were saying 25hz is not enough data 😆 ohhh, the context that can be missed via text
I asked ChatGPT to explain a Dockerfile to me. The attached PDF is our chat. The dockerfile is in the thread.
Any docker experts care to confirm the explanation? cc @keenin. Looks reasonable to me but I’m no expert. This is supposedly an example of a multi-stage build that copies only the necessary artifacts to the final image in order to reduce its size, from Lyft’s infra team.
Ooo that is a cool use case. Been busy, but will hopefully find time to look at the dockerfile and the gpt response about it soon
without going over it with fine-toothed comb, honestly, it seems to explain it pretty well.
Yea sense accurate. But also just seems like chatgp is just replacing the commands with text lol. cd -> file is changing directory from arg0 to arg1
I read hacker news sort of obsessively. i organize things i read with readwise.io/read. i also listen to tech podcasts almost daily. anything that catches my interest i usually try using/doing hands-on at least once
I also am pretty selfish when it comes to things I do at work. I’ll go out of my way to develop a nice-to-have feature for myself/my team, which usually gets me experience with things not strictly used in the day-to-day
How do you decide what to read on hacker news? Just scan from the top? Or...?
Yeah, usually just anything on the front page that interests me. I also subscribe to their "best" feed which lands in my reader feed.
I don't use the original readwise app at all really. Don't do much highlighting or taking notes. I use their reader app, which I really like. It's quite polished and supports a ton of content/media types. Any RSS feeds I subscribe to land in there, and then whenever I come across an article online I want to read, I add it to reader. The tagging system is really good IMO and allows me to organize/archive content I've read easily. It also has a built-in gpt-3 feature ("ghost reader"), which is neat. You can ask gpt to summarize the article, or define a word or something, in the context of the article on whole
That aggregation ability of the reader app interests me a lot. Gonna give it a try. Thanks for the recommendation!
Also, what are some of your fav feeds you have hooked up to Reader?
Have you looked into anything else on pragmatic engineer besides the blog? Like the job board, etc...?
Also, do you pay for pragmatic engineer newsletter and find it a worthwhile ROI?
I haven’t looked at anything beyond the blog. I just discovered it, so I’m just reading the free tier articles. The pay walled stuff sounds really interesting though
Another thing about reader that I really like is how they handle YouTube videos. I hate watching videos. I much prefer reading text content. Reader produces a transcript so I can take a YouTube video and treat it like an article instead. And if you want to watch the video it will auto-scroll and highlight the current transcript blurb accordingly, like karaoke.
Yeah, I'm gonna start w/ free tier and then evaluate. The article titles seem interesting.
I actually really like video format, but that is a really cool feature! I have more time to listen to videos (running the dog, etc...) than I do to read.
I think the most valuable thing for me is the archiving and tagging. No more losing old things I’ve read. Also getting around paywalls is nice
They gave me a new 30 day free trial 🙌
I keep forgetting to try this out
@brandon here maybe this is a good starting point:
It was at one point up-to-date but I’ve since been like fuck it I’m not setting up new macs all the time so it’s gotten out of sync because I do some adhoc shit for each laptop. But it’s got some okay stuff in there. Look at the README and all the files. It addresses your ssh config as well.
github bot is wrong it wasn’t updated a year ago it was updated a few minutes ago
np. will update this thread with stuff i think of
mac os specifics
# brew is the package manager
brew install
brew info
brew upgrade
brew update
brew list
# clipboard
pbcopy # e.g.cat ~/.ssh/config | pbcopy
pbpaste # e.g.pbpaste > ~/.ssh/config
# manage any macos setting with thedefaultscommand
defaults read # list settings
defaults write # update settings
# for example, sort activity monitor results by cpu usage:
defaults write com.apple.ActivityMonitor SortColumn -string "CPUUsage"
defaults write com.apple.ActivityMonitor SortDirection -int 0
# or, don't show recent apps in dock
defaults write com.apple.dock show-recents -bool false
# i hope you don't have to ever really use or think about plists, but if you do:
alias plistbuddy=/usr/libexec/PlistBuddy
alias plist='plistbuddy -c "print"'
don’t sleep on the zsh history lookup! control+r and then start typing
unlimited zsh history:
HISTFILE="$HOME/.zsh_history"
HISTSIZE=10000000
SAVEHIST=10000000
setopt BANG_HIST # Treat the '!' character specially during expansion.
setopt EXTENDED_HISTORY # Write the history file in the ":start:elapsed;command" format.
setopt INC_APPEND_HISTORY # Write to the history file immediately, not when the shell exits.
setopt SHARE_HISTORY # Share history between all sessions.
setopt HIST_EXPIRE_DUPS_FIRST # Expire duplicate entries first when trimming history.
setopt HIST_IGNORE_DUPS # Don't record an entry that was just recorded again.
setopt HIST_IGNORE_ALL_DUPS # Delete old recorded entry if new entry is a duplicate.
setopt HIST_FIND_NO_DUPS # Do not display a line previously found.
setopt HIST_IGNORE_SPACE # Don't record an entry starting with a space.
setopt HIST_SAVE_NO_DUPS # Don't write duplicate entries in the history file.
setopt HIST_REDUCE_BLANKS # Remove superfluous blanks before recording entry.
setopt HIST_VERIFY # Don't execute immediately upon history expansion.
setopt HIST_BEEP # Beep when accessing nonexistent history.
fave tools
install with brew ()
- bat is like cat, but better
- ripgrep is the fastest recursive grep you’ll ever use. command line via rg
- gh is the github cli you didn’t know you needed. really great. and an awesome example of what you can make using the charm terminal-app suite.
- json:
- jq
- jqp
- gron
- jless
- tree
- ffmpeg
- youtube-dl
- micro is like nano, but better. defaults to windows keybindings if you’re missing those.
- jenv for managing java environments (pyenv for python, rbenv for ruby)
- yq is like jq but for yaml
- xml processing: xmlstarlet
- essential: pre-commit
- build better clis:
- real-time zsh syntax highlighting: brew install zsh-syntax-highlighting
cheat.sh is an awesome website, made even better via terminal
# Cheat on commands e.g.cheat jq
function cheat() {
curl -s cheat.sh/${1} | bat -p
}
if you want to go hard with zsh extensions/customization, check out https://github.com/ohmyzsh/ohmyzsh
I personally don’t want all that as a dependency, so I cherry pick what I like and vendor-in the specifics
https://brew.sh/2023/02/16/homebrew-4.0.0/
Brew 4 is released. Particularly happy to see this:
brew update will now be run automatically less often (every 24 hours rather than every 5 minutes) and these auto-updates will be much faster as they no longer need to perform the slow git fetch of the huge homebrew/core and homebrew/cask taps’ Git repositories.

If you also have a teammate who has an unbreakable habit of pre-maturely resolving all comments on a PR, here’s a tampermonkey script I created to open up all resolved comments upon page load, and also made it accessible as a ctrl+d keyboard shortcut:
(a userscript engine like tampermonkey is required for install)
Non-install link to the gist in github:
I have the opposite problem, where folks don't click "Resolve" even after the convo has been resolved, so it is hard to tell which threads still need a resolution 😆
i admit i don’t always remember to resolve them. figure better to forget to resolve than resolve too early
it is ok to forget some, but most folks on my team never click the Resolve button lol
like, this guy, he will resolve comments before the changes have been made. he’ll even comment “fixed” and then hit resolve. but the changes have not yet been pushed from his local checkout
hahaha yeah, i hate that too. like wait until you push the change before you say it is fixed, duh!
me, my other teammate, and my manager have all asked him to stop but he just can’t help himself
@brandon because you said you’re good with javascript. how do i make it so my script runs every time i click “Show more hidden items” buttons

he will resolve comments before the changes have been madeHow long does he wait though? Cuz, I'll admit, I've sometimes hit resolve while changes are still local but that's when I'm using it as a sort of checklist and know I'll be pushing the changes shortly
This was discussed at length in chat the other day (to @keenin’s dismay), but I'll repeat my verdict here for the record! In almost all cases, the comment should be resolved by the author who requested the change and all comments should be resolved prior to merging the PR. Otherwise, you don't have confirmation that the author of the request is satisfied with your solution. This requires continuous collaboration between the commenter and PR author though so there has to be an agreement in place. My new team isn't aligned on this... yet.
Okay, one small downside to my tampermonkey script that I just experienced. There was a resolved comment thread, of course, that I commented on and requested him to revert the changes. It wasn’t until I came back to the PR after a meeting that I realized my comment would not be obviously apparent to readers because it was an already resolved collapsed thread. So I had to unresolve it myself, which I didn’t do originally
the comment should be resolved by the author who requested the change and all comments should be resolved prior to merging the PRAgree, but I don't think I've ever seen anybody on my team resolve their own comments...
Do you all use statsd for your metrics emission/collection or something else?
collectD process, w/ statsD plugin, and dogStatsD flavor....to be specific
thanks. can’t say i’ve heard of the other two you mentioned
collectD is a generic plugable daemon. So, it accepts a statsD plugin, which minics exactly the statsD interface and functionality. But collectD can also run all sorts of other plugins.
DogStatsD is an extension to the statsD "language" to enable tags/dimensions to metrics.
Oh maybe we use something like DogStatsD, cause we also have tags/dimensions e.g.
stats.incr(
'upload_request',
tags={
'report_source': report_source,
'report_platform': report_platform,
},
)
yeah, looks like it. If you can filter a specific metric by additional tags, then you are prob using dogStatsD
history is statsd was developed and open sourced by Etsy. Then DataDog picked it up and released (as open source) a new backwards compaible "flavor" (dogstatsd). I love open source for this reason.
It is usually just a config setting to switch between the flavors. Most things default to dogstatsd now, since it is backwards compatible, so doesn't hurt to have more available functionality 🙂
@keenin i use starship.rs for my zsh theme management. it’s built in rust so super fast. although i set my transparency to 10%. i feel like you would like the tokyo night preset. i also like the pastel powerline
brew install starship
echo 'eval "$(starship init zsh)"' >> ~/.zshrc
Also I use the mocha color profile from



i use fira code nerd font
brew tap homebrew/cask-fonts
brew install font-fira-code-nerd-font
Without knowing what Powerlevel10k was written in, I figured the Rust implementation would be faster, but the creator of p10k claims it's still faster in this post 😮 Seems like they are both great options though according to the zsh community.
Eh, here's another perf post where starship is faster. Funny enough, it uses the perf tool built by the author of p10k.
brandon idk why but i’m getting strong 90s windows sysadmin or dba vibes from that theme lol
Oh man, this is awesome:
I’ve wanted something like for a long time. I have plenty of interest in spinning up a project with a web front end, but I have zero desire to learn JS/react/whatever frontend framework and don’t view it as a good investment of my time. But now with this, I don’t have to! Super excited to try this out
Website: (built entirely from pynecone, other examples in their gallery)
HN launch:
Yeah! It actually looks well done. I’ve seen similar attempts but nothing that looked as promising as this
Wow, that's very cool. Microsoft has blazor for the .NETers, but I think there is more templating required maybe? Hard to tell. Integration with React? Also very cool. I do wonder how much control you'll have out of the box without doing a lot of custom css and templating though. But, if you just want a basic web app for a personal project, this seems great!
I understood the project as no CSS or templating needed. At least not truly. You control the appearance through their Python abstractions.
I see a small dictionary with some values, but other than that I don’t see any css/templates in the source code for their gallery websites e.g.
no actual css or html from what i can tell.

people here use vs code, right? how can i add a custom command so that i can run a shell command with the current editor filename passed as input (via right-click or keyboard shortcut)?
Figured it out.
- Add task configuration to tasks.json
- Add keybind configuration to keybindings.json
- Optionally update the When condition in the Keyboard Shortcuts editor

Oh you can do step 3 directly in keybindings.json
Not yet, looking into it is on my to-do list though. Lyft recently migrated from OpenTracing+Lightstep to OpenTelemetry+X-Ray, and I want to get my team onboarded because we have no tracing right now.
I'm integrating our service with Zipkin via Otel. I've got the basics working, but trying to figure out how to have Otel always send "slow" and failed request traces. Currently it just does a flat sample rate across all requests.
My team also doesn’t have tracing setup. Would love if Ryan you learn all the ins and out and then do a lunch and learn for me
Also in the process of implementing OTel. Will report back in 6 months 😄
Eh, I don't have a timeline but just figured that's about when I'd have enough battle tested experience to give you good advice. Sounds like you'll beat me to it though!
For sure 😄 Just giving you a hard time. I'm moving slowly, since I'm only working on it in spare time.
What i've learned so far:
- Take advantage of auto-instrumentation. Only after auto instrumentation would you want to rely on manual.
- Salesforce tooling doesn't currently support a static sample rate (e.g. 1%) for "normal" requests, and to send all slow and failed request traces, but it is totally possible, so I recommend seeing if your tooling supports it.
Do your teams outline a monitoring/alarm/metrics standard?
For example how do you treat a lack of metrics: do you alarm or consider that okay, and when is that okay?
On top of that, is your standard to have services emit a 0 on success and 1 on failure, or only emit for failures, and again, when and why?
Our current standard is just how the engineer felt when adding or modifying the metric, alarm, or monitor.
For example how do you treat a lack of metricsWe alert on no-data, but with a longer inertia (maybe after there is no data for 10mins), where as we would alert on error immediately or after 1min.
is your standard to have services emit a 0 on success and 1 on failure, or only emit for failures, and again, when and why?To satisfy the previous no-data alerting, you have to emit metrics on success, otherwise you can't tell the difference between success and no-data.
Happy to answer any more specific questions on how we do it. Hopefully I can learn something from how you do it as well 🙂
My team is pretty similar to Sam's. We emit metrics at the end of most flows to track usage, and we alarm on sudden changes in metrics (both up and down, in some cases), zeroes in success metrics, and error rates. The exact times and rates vary by service though.
Right, so my question goes beyond your current setup to an actual living standard that is known by your team when creating a new metric/monitor/alarm. Basically, can you tell me that you are 100% certain all of your alarms and metrics work like this or are you going to find some odd ball cases if you do an audit?
Oh, oddball cases, for sure. I haven't even setup alarms for the feature I added awhile ago yet. This is just the expectation, we don't have any systems in place to verify it.
We absolutely have success/failure metrics for any new feature added. No one can say they are done with a feature until that happens. The no-data part could slip through, but is generally caught during code review when configuring the new alerts.
^ just reminded me of a caveat: every new feature is initially released with experimentation, so we are very aware of usage immediately after release. I do now wonder if this makes us more lax on alarms though 🤔
Yea like you only create alarms for things you witness in the experiment.
For example how do you treat a lack of metrics: do you alarm or consider that okay, and when is that okay?We do alarm on no-data. It’s annoying to get the PromQL right for this though. PromQL is one of the things I hate most in tech.
On top of that, is your standard to have services emit a 0 on success and 1 on failure, or only emit for failures, and again, when and why?We have three types of metrics:
- stats.incr(): emit a counter
- stats.timer(): time an execution and emit percentile measure p50, p95, p99, p999
- stats.gauge(): tbh i’ve never used this i don’t know what this does
So when you ask emit a 0 on success and 1 on failure, it’s more like stats.incr('mymetricname.success') and stats.incr('mymetricname.failure') or something to that effect. My team emits a stat at almost every step of the pipeline. We have too many arguably. When we don’t use them for a long time they get blocked by our systems to save on costs.
We also have a ton of auto-generated alarms for generic observability. Like cpu/mem usage. k8s autoscaling/replication. Endpoint request volume. Logging level error counts. http exception stats
Right, so my question goes beyond your current setup to an actual living standard that is known by your team when creating a new metric/monitor/alarm.Lyft has standards that are company wide. Our infra is actually really good for the size of our company, and has really good docs. s/o to the infra org. Aside from the auto-generated alarms previously mentioned, it’s still up to individual contributors to ensure good alarm coverage. But observability is hammered in pretty hard during eng onboarding. But, per usual, good PR reviewers have to comment on it if they are missing.
Basically, can you tell me that you are 100% certain all of your alarms and metrics work like this or are you going to find some odd ball cases if you do an audit?Fuck no. We’ve had many sevs due to alarms not working as expected. Not my team (of course). But across Lyft
- stats.gauge(): tbh i’ve never used this i don’t know what this does
A counter that can decrement, for monitoring something like current connections. Never used it either though
That’s good to know! I want to think of a use-case to use it on my team
counter is monotonically increasing. gauge is a number that can bounce around.
Do yall's codebases makes use of AOP? If so, what functionality do you do w/ AOP (e.g. metrics, logging, etc...)?
Hmm. I have not heard of aspect-oriented programming before now. But reading the wikipedia page on it, it sounds like my team might do some of it without thinking about it as AOP. It almost sounds like a fancy word for monkey patching. I wouldn’t say it we do this sort of thing a lot, on the contrary, I try to minimize certain classes of side-effects.
The example of logging is one I’ve done before. Where I wanted to automatically log all the calls of a certain classes methods, so rather than modify the code of the class and its methods, I monkey patched the class so when one of it’s instance methods are called the function and args are logged. Does that count?
Some things at Lyft that are widely monkey-patched are Flask apps and gevent greenlets. Basically the first thing you do when starting your application is monkey patch Flask and gevent, and then you go and load your core app modules that use them.
I could be totally misunderstanding AOP though. Do you do it?
Your example of automatically logging by "monkey patching" the class, sounds like AOP.
AOP when done right, usually supported by a framework, seems like it can really keep a code base cleaner. We use it in a few places (e.g. implementing db call retry logic). I'm looking at using it for wrapping method calls in Spans for distributed tracing.
Would applying a decorator to a function be considered AOP? Like suppose I have a decorator that modifies a function to log the name/args prior to executing the function when it’s called. like
@log_function_calls
def my_elegant_function(args, kwargs):
# do stuff
return something
The logfunctioncalls decorator is applied to myelegantfunction so when myelegantfunction is called, it logs it. Wikipedia says AOP doesn’t modify the function code directly, but this decorator approach is applied at/near the function definition, very close to the code. I guess it achieves the goal of AOP, separation of concerns, but idk if formally AOP has a more strict definition.
Sounds like AOP to me! I think decorators would be considered one of many ways to connect the Aspect to your code.
I'm using decorators as well for my use case. They seem like a good way to tie in the Aspect
Now you can claim you are using AOP rather than monkey patching and sound legit 😊
Had to review definition of AOP as well, but given that I'm using Java/Spring, I think it's safe to say that I do a lot of AOP! Everything's a decorator! .NET was similar, but less extreme. I think it was a better balance. The Java ecosystem just takes it too far sometimes. So much black box magic going on everywhere. You have to memorize the side effects of all the annotations/decorators to know what you're dealing with.
Does anyone use Github Desktop? I remember checking it out and not finding it helpful, but wondering if I might be missing something.
I don’t use GH Desktop, but I do use the great GitHub CLI every day:
https://github.com/cli/cli
Amazing ls/du/tree/find-in-one CLI tool so incredibly named after Elden Ring, erdtree:
https://github.com/solidiquis/erdtree

the problem as i understand it is that AWS Lambda is degraded. Lambda is used by AWS in the backend for many of their other services. Notably for me/Lyft, we are unable to authenticate reliably, hitting credential errors when trying to assume IAM roles

Posted using /giphy | GIF by GIPHY Studios 2021
Damn, missed this thread yesterday haha but yeah, our lambdas and STS were also causing a bunch of issues. We even had tangential issues with scaling up resources and deploying. Please link to the post mortem if/when it's released!
Would have liked a bit more low-level details, but still an interesting read! I love technical blog posts from companies, even if they are just recruiting vehicles. I guess they work lol
https://slack.engineering/real-time-messaging/

Thanks for sharing. I'll give this one a read. I appreciate when companies do that as well. I read some of Uber's back in the day.
Uber had a great blog! I wonder if they still do, I haven’t looked in a while
Woah this is pretty cool https://eruda.liriliri.io/ (for mobile browsers)
Just deleted 300+ TB of data. Feels good
It was a compaction service we had spun up just before the Nov 2022 layoffs, which resulted in me being the sole engineer on the team. Then we got an eng from a sister team to assist 20% of their time on the service. Then April layoffs happened, and he and my other new teammate were let go. Back to me being sole eng. So we decided we couldn’t support this project anymore. I turned off any new compaction back at the start of May, but just got around to deleting all the compacted data it had produced just now. It was live Sep 2022 - Apr 2023, compacting all telematics signal data as it came in to a condensed, easier to use format. Would have liked to keep it going and support it full-time, but just don’t have the resources
Oh man, you had me thinking it was an accident in the first half lol I was very worried.
lol oh boy that would be a lot of data to accidentally delete
For the last week or so been trying to debug why GPS sensor timestamps coming from a new device we’re launching don’t line up with the sensor timestamps we record on the driver phone, for the same recording period. They’ve been consistently off by approximately 19 seconds. Been banging our heads as to why.
Yesterday the device firmware team made the brilliant statement: “the GPS uses GPS time….” Okay?!?! So what, the time coming from these two different devices be roughly the same, maybe within +/- 10 microseconds… right? Oh, but no no sweet summer child, they said. GPS time is different, they said…
Fucking news to me.
GPS time does not includes leap seconds.
Okay… good to know but not helpful, I said. There have been 27 leap seconds inserted into UTC since epoch (1970). But we are off by 19 seconds, so thanks for this random piece of trivia.
GPS time uses a different epoch, 1980
Fuck me. Of the 27 leap seconds since UTC epoch, 9 of them occurred in the 1970s, before GPS epoch. Thus, leaving 27 - 9 = 18 leap seconds ‼️
But that leaves one second unaccounted for
We are, after all, 19 seconds behind, not 18. Turns out there is often around a 1s delay between when the time measurement was taken on the other device GPS module and when it gets routed through bluetooth to the client (driver phone), and we anchored those timestamps to the client receive timestamp. Off by one second. 18 + 1 = 19 💡
Mystery solved. It all does line up, once we account for these clock differences
Gotta admit, I felt real dumb not knowing GPS time was a different clock altogether. I just thought it meant the normal time coming from the GPS lol I know absolutely nothing and can’t believe people trust me to do this stuff
Holy shit, that is an amazing example of why dealing with time is difficult
Yeahhhh never do your own date/time management if you can avoid it
Python slicing is relatively performant, so in your case, I think if you can assume a non-empty string, I like your third option. Except, I’m not sure why it has to be an open-ended slice. Would x[-1] be sufficient?
Seems like a strange problem though. From readability perspective, I might just go with 'b' in x
Although, if x is literally ever only 'b' or 'a,b', you don’t need to check for existence of 'b', because you know it is guaranteed
I was trying to keep it simple and I can't edit the poll to clarify, but the possible values are more like:
- xyz
- abc,xyz
- qrs
- abc,qrs
I think in actually does? My testing env is 3.x though and we're using 2.x
I saw that, but for some reason thought it'd only check characters, not substrings
i assume it uses the python string contains method, which checks substrings

---
⚙️ Results revealed after closing
Created by @r.taylor with /poll
🔒 This poll is now closed
Anyone use devdocs.io for documentation? I’ve been really liking it
Interesting, never heard of it. So it's just a bunch of docs indexed in one place. It looks nice.
Yeah, I like it. It has an offline mode with is nice. And loads of keyboard shortcuts. The open-source Python docs are particularly bad, hard to browse. So this is a really nice alternative. I’ve setup Kagi to redirect all docs.python.org search results to the proper devdocs.io/python link
Yeah, my IDE also has docs presented. It’s nice to hover over and get them, or pin them on the side
But I always find myself just opening up the links. Not sure why but I like a separate window
@brandon now that you’re trying out Kagi, I’ll share my redirects for examples/inspiration.
I use these so any docs.python.org links redirect to the appropriate devdocs.io link:
# Links without a minor version
^https?://docs.python.org(?:/\d)/(.?)?(?:.html)?(/?#[^#]+)?$|
# Links with a minor version
^https?://docs.python.org/(\d.\d+)/(.?)?(?:.html)?(/?#[^#]+)?$|

how can i tell if my system is compromised?
a security guy at lyft said there was a chance my system was compromised due to some connections made to a malicious domain. he said there was a chance i had my data exfiltrated, and that it might be good to change my password just to be safe, but he didn’t see the hard proof that he saw with other people who connected to the site. only a few minutes later my slack app quit out while i was actively typing a message (and no i didn’t hit cmd+q). if slack had crashed unexpectedly, would it report it to me anywhere? i’m used to apps reporting that they crashed and asking for permission to send crash details/diagnostics back to HQ ™️ for better understanding what went wrong. Slack didn’t do that
Pedro Gonzalez [3:31 PM]
Hello Kyle, I’m investigation suspicious emails that tried to collect some data from us, using carrier.formcarry.com do you use this service or recall to use it in last 30 days?
Kyle Andelin [3:33 PM]
I have never heard of carrier.formcarry.com (edited)
Pedro Gonzalez [4:58 PM]
It’s weird I don’t se also any emails coming to you so I don’t think its related, but I do noticed that there was a request to this domain from your device, the domain is legit but was used to create a form and then exfiltrate info, if you do not recall to visit the site I would suggest to change your password just to be cautious
Kyle Andelin [5:00 PM]
oh snap
[5:03 PM] so carrier.formcarry.com is a website people typically access in their internet browser? and it then proceeds to exfiltrate certain user data?
[5:03 PM] do you know if the data is restricted to browser data or is it the rest of my system as well?
[5:04 PM] and it’s my macbook the request came from?
Pedro Gonzalez [5:05 PM]
Yes the trick was to make the user open a malicious file than then sent the data to this site, but in your case I did not see the file nor the email that was sent to other internal directions, just that your browser resolve the directions DNS, this could be because other legit site used for legit purposes but theres a little chance that maybe you received in another form, right now theres no evidence that suggest that your system or something else is compromised
Kyle Andelin [5:08 PM]
very curious. thanks for reaching out. i’m gonna snoop around my system to see if i can see the request at any point
Pedro Gonzalez [5:09 PM]
Thanks, I have this date: 09-28-2023 05:02:59 pm UTC
[5:09 PM] for the connections
Kyle Andelin [5:09 PM]
brilliant. thanks
Ah, gotcha. It sounds like the site is used for legitimate purposes as well and you didn't have the problematic file or email in your inbox so there is no reason to think you were compromised necessarily. Hopefully he would have been more aggressive if there was more evidence. And it sounds like the nature of this attack is that they collect a static snapshot of data and push it out to an endpoint for collection. I don't think you need to be worried about your system being compromised unless they have used that data to hack in further, thus the advice to change your password just in case.
Either way, you have record that the security guy reached out and that you did everything that was asked of you, so if anything comes up later you'll be covered.
do you think the hacker tested is access levels by trying to close an active process that i spawned (slack)? If indeed my system is already compromised, who’s to say he hasn’t implemented a permanent backdoor and my password now is irrelevant
how do you guys come up with passwords for things outside the scope of password managers? like your laptop user password. i can’t memorize an actual strong password
Well, then you're fucked 🙃 Just do what IT says to cover your own butt. I really doubt you were compromised though. There are better ways for a hacker to check their permissions.
I'm not great at password generation. I just have patterns that I rotate through based on the context.
Surprisingly easy to memorize sixteen random characters, especially if you type them every day
And all secrets are in the scope of password managers, they aren't just for autofilling
 <a href="https://github.com/curl/curl">curl/curl</a>
<a href="https://github.com/curl/curl">curl/curl</a>
What version of curl are you guys on? I just checked after seeing this post
❯ curl -V
curl 8.1.2 (x86_64-apple-darwin23.0) libcurl/8.1.2 (SecureTransport) LibreSSL/3.3.6 zlib/1.2.12 nghttp2/1.55.1
Release-Date: 2023-05-30
Protocols: dict file ftp ftps gopher gophers http https imap imaps ldap ldaps mqtt pop3 pop3s rtsp smb smbs smtp smtps telnet tftp
Features: alt-svc AsynchDNS GSS-API HSTS HTTP2 HTTPS-proxy IPv6 Kerberos Largefile libz MultiSSL NTLM NTLM_WB SPNEGO SSL threadsafe UnixSockets
8.1.2, 2023-05-30. This is way more recent than I was expecting. I’ve never thought at all about curl upgrades and didn’t even know they were happening in the background. 8.3.0 was released three weeks ago though, and now that I’m aware I’m impatient where’s the upgrade
I remember thinking those were behind us when I learned about them
Unix time reaches 1.7B
https://www.epochconverter.com/countdown?q=1700000000
Every piece of data on your mac is of a certain type, defined by its UTI. How an application interacts with a piece of data is UTI dependent.
An app can define its own UTI types and can choose to export them to the system or keep them private. A tool I use to see what UTIs are available on my system, what apps use them, and change what app should be the default handler for a given UTI is . It adds a new System Settings pane serving as a UI to these things + URI schemes (Uniform Resource Identifier is the original, technically correct term, but most everyone uses URL scheme interchangeably, including Apple). It also includes a CLI








Anyone running ollama locally to do RAG on your docs or code or whatever?
Just making sure I'm interpreting this correctly. You basically want a custom LLM that has the context of your docs and source code, right?
This sounds super cool. I feel like there are some enterprise solutions, but a self hosted open source option that could be plugged into confluence and GH would be great!
yeah, It can be a non-custom LLM, like Llama models, but with a RAG layer on top to feed in my personal docs and code and such.
Trying ragflow now 🤞
If you use Obsidian for notes, it has a "Smart Second Brain" plugin which you can hook up to Ollama running locally. But I want it to have context beyond just my Obsidian notes, so trying this out. WIll report back.
Have you tried the obsidian one out? That would be cool, although I'm unsure about feeding it work related stuff. Would have to learn more.
I haven't tried the Obsidian one yet.
The motivation for running Ollama locally is nothing leaves your laptop, so you can feed it work stuff, code, docs, etc..
One of my coworkers is using Ollama and Open WebUI and says it is working great. I might try that next.
That's cool. I'd love to mess around with more of that stuff, but my company policy is still pretty strict on usage of AI tools so I'm not sure it's worth it. I think the policy is mostly targeted toward using AI generated content in our products/services, while this would just be a fancy way to grep notes, but I don't want to risk it 😬
OpenWebUI + Ollama works so far.
Easy to add local docs and ask questions against them.
Will try asking about code next



FYI for anyone who uses iterm you should update to 3.5.11 ASAP. The security vulnerability is stunning:
I’ve used iTerm for the last several years and definitely impacted by this edit: maybe not actually after reading the notes more closely. Extremely disappointing. Coincidentally, last week I started using ghostty as my terminal emulator. So I guess I was already out the door anyways.
Diff for the fix is short:
- gnachman/iTerm2@014ba7e Disable
- gnachman/iTerm2@63ec2bb Removal
Looking at it… just why even in the first place
holy shit, we got Cursor licenses for work, and my mind is legit blown. i've only been playing with it for a day, but it is so much better than i imagined
It's like having an okay-ish engineer who can take instructions, go work for a few minutes, give you a small PR, and you either accept or decline it.
Cursor is all the rage online. Haven't tried it myself!
Yeah I was suspending belief until I tried it. Far exceeded my expectations. This is easily as big of a step function improvement as when chatgpt first came out. I can see it becoming an expectation for people to develop much faster.
Salesforce hasn't been super fast at giving us access to frontier AI, so I'm pleasantly surprised they gave us cursor already
I'm out of touch with company practices. Is it normal for companies to make the suite of all GPT-like products available internally?
Wow, just watched some videos showing MCP usage in Cursor for browser and terminal and github interactions. This is insane. I was aware of MCP, but I didn't realize it was being used in products yet. I gotta get this set up tonight. I've been rerunning UTs and pasting the errors into cursor, so hopefully I can just get it to rerun the UTs automatically and iterate on the errors.
Give it a try on a personal project, just to see what it's like. My mind keeps being blown. I really expect to spend a majority (not all) of my time prompting ai, reviewing code from AI, and repeat, instead of writing code. I didn't think that until the past few days.
I'll take a look at it today!
For work/prod code, there will def be more time spent reviewing/refactoring/editing the AI code, at least for now. But I vibe coded a tool for querying github PRs last night and I did days worth of work in a few hours. So weird
Wow, that's incredible. We just got access to enterprise ChatGPT last week as well. It's already come in handy a couple times, but what your describing sounds incredible.
Having access to an LLM chat interface is such a huge improvement. We only got that a month or two ago with Gemini. Being able to put your code and docs into it is so helpful. Id be happy to do a demo for you of cursor, but youtube can probably do better than me 🙂
Yeah, the Google Drive integration is pretty sweet. I want a Slack and Confluence integration too. Also, it would be even better if I could ask it to show me documentation on a particular topic instead of having to hand feed it the doc I want it to process.
Got my first MCP server working with Cursor. This paradigm is gamechanging. Soon, your AI will be able to connect to all of your tools and it will become even smart and more aware of your context.
That's cool. Does your employer bless and encourage these integrations? Also, what type of MCP server are you connecting to? I'm not too familiar with the term.
We're ramping up on ChatGPT over here and it's been awesome, and that includes integration with Google Drive built in. However, the AI model needs to be hand fed individual documents of interest so it's not nearly as powerful as what you are describing. I naturally want my model to have access to Confluence, GitHub, Google Drive, etc by default. However, I can't expect it to scan through all of those sources every time I ask it a question. How does it decide which sources to consider in it's response?
And then whoever owns the AI will own your company!!! Muahahaha!!! SKYNET 1.0!!! evilparrot
wake me up when I can just turn off my braingetting close 🙂
I started with the open source github mcp server. im following on whether they bless the usage of open source MCPs or if they're gonna have like a list of vetted ones or something like that.
It's the opposite. It enables you to multiply your skills. It makes it so you can spend the time thinking an architect viewing rather than figuring out syntax and actually typing the code your fingers.
However, I can't expect it to scan through all of those sources every time I ask it a question. How does it decide which sources to consider in it's response?I havent integrated it with like a large document source (like g drive) yet so I'm not sure because even indexing that large of a document source doesn't seem feasible. But it does index your repo that you have open so it basically has a lay of the land of the entire repo and all the files in it.
That's a lot of architects! I guess as long as I stay ahead of it, I can still stay relevant even if a lot of the lower tier jobs disappear. It's going to change the job market for sure!
wake me up when I can just turn off my brain
getting close 🙂 (edited)But seriously, it's gonna turn each one of us into architects who rarely ever if ever actually right code and we just tell the AI what needs to be done and review it and architect.
Like we are way closer to that point than I would've thought a week ago
It will allow us to think about much more interesting problems without having to worry so much about the minutiae.
You may still need to worry about the detail details, but instead of implementing it yourself, you just review the output and make sure it is as you would like it. Again, very similar to us if you had a team of engineers working for you where you just review their output and tell them what to do
I started with the open source github mcp server. im following on whether they bless the usage of open source MCPs or if they're gonna have like a list of vetted ones or something like that.Nice, that's cool that you feel comfortable integrating with open source tools to try things out. They have been pretty strict with us so far, but it's only week 2.
well, im not doing too much with the MCPs until i get the green light. there are internal teams working on vetting and hosts MCPs, so i suspect they will want us to use those.
Ok, I'll try to be more optimistic. But I want to keep my brain on, that's what keeps any average joe from doing my job, which keeps me in demand, which I like 😁
I wonder if pull requests are going to get more tedious if people are pushing out code more quickly. Well actually, the pull requests will probably be reviewed by AI too 😆
we will of course review production code, but for small tools, it can take minutes to a few hours to build what would have taken days to weeks. i don't even know html/javascript 😄

That is super cool. I'd love to hear more about your "vibe coding" process here.
If you have any favorite resources on how to do that most effectively, please share!
video with this guys' tips on coding with AI

Yeah, that works. I might be slightly late coming back from the gym around that time.
Sam and I can cover stuff you went over yesterday til you show up
import tariff
# Set your tariff rates (package_name: percentage)
tariff.set({
"numpy": 50, # 50% tariff on numpy
"pandas": 200, # 200% tariff on pandas
"requests": 150 # 150% tariff on requests
})
# Now when you import these packages, they'll be TARIFFED!
import numpy # This will be 50% slower
import pandas # This will be 200% slower
Why TARIFF?
Because foreign packages have been STEALING our CPU cycles for TOO LONG!
lol



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I hadn't heard of fzf. Have you?
@andelink introduced this to me when I switched to mac a couple years ago. It's been so long since I set it up that I don't even know which parts it is contributing, but it's definitely installed in my shell!
nice. it seems like something i should have known about, or thought to search for, a longggg time ago :face_palm:
I think there is another plugin that integrates with fzf, but I can't remember the name
there are many. the one i most recommend is fzf-tab. it hooks into zshs native completion system so that every time you hit